Jessica Fjeld is a Lecturer on Law at Harvard Law School and a Clinical Instructor in the Cyberlaw Clinic at the Berkman Klein Center for Internet & Society. Mason Kortz is a Clinical Instructional Fellow at the Clinic.
This Comment is the first in a two-part series on how lawyers should think about art generated by artificial intelligences, particularly with regard to copyright law. This first part charts the anatomy of the AI-assisted artistic process. The second Comment in the series examine how copyright interests in these elements interact and provide practice tips for lawyers drafting license agreements or involved in disputes around AI-generated artwork.
Advanced algorithms that display cognition-like processes, popularly called artificial intelligences or “AIs,” are capable of generating sophisticated and provocative works of art.[1] These technologies differ from widely-used digital creation and editing tools in that they are capable of developing complex decision-making processes, leading to unexpected outcomes. Generative AI systems and the artwork they produce raise mind-bending questions of ownership, from broad policy concerns[2] to the individual interests of the artists, engineers, and researchers undertaking this work. Attorneys, too, are beginning to get involved, called on by their clients to draft licenses or manage disputes.
The Harvard Law School Cyberlaw Clinic at the Berkman Klein Center for Internet & Society has recently developed a practice in advising clients in the emerging field at the intersection of art and AI. We have seen for ourselves how attempts to negotiate licenses or settle disputes without a common understanding of the systems involved may result in vague and poorly understood agreements, and worse, unnecessary conflict between parties. More often than not, this friction arises between reasonable parties who are open to compromise, but suffer from a lack of clarity over what, exactly, is being negotiated. In the course of solving such problems, we have dissected generative AIs and studied their elements from a legal perspective. The result is an anatomy that forms the foundation of our thinking—and our practice—on the subject of AI-generated art. When the parties to an agreement or dispute share a common vocabulary and understanding of the nature of the work, many areas of potential conflict evaporate.
This Comment makes that anatomy available to others, in the hopes that it will facilitate productive negotiations and clear, enforceable agreements for others involved in AI-related art projects. We begin by clarifying what we mean by AI-generated art, distinguishing it from art that is created by humans using digital creation and editing software. Next, we describe four key elements that make up the anatomy of a generative AI. We go into detail on each element, providing plain-language explanations that are comprehensible even to those without a technical background. We conclude with a brief preview of the second Comment in this series, which will delve into how we think about the application of copyright law in this context, including the questions of ownership that arise as to each element, and provide some practical insights for negotiating agreements in the context of AI-generated art.
I. What is AI-generated Art?
“Art” and “intelligence” are two notoriously difficult terms to define. As such, it is no surprise that the boundaries of AI-generated art are unclear. One might define a generative AI as a “computational system[] which, by taking on particular responsibilities, exhibit[s] behaviours that unbiased observers would deem to be creative.”[3] For this article, we add some additional limitations to the scope of our review. First, we only consider systems that use machine learning to develop an algorithm for generating outputs, not those that are programmed with a preset algorithm.[4] Second, we assume that the machine learning process involves training on existing works. This excludes forms of machine learning that start “from scratch,” like some evolutionary algorithms.[5] Finally, we assume that the algorithm generated by the machine learning process, when run, outputs works that are both novel—meaning that they are not copies of any existing work—and surprising—meaning that the output is not a predictable transformation of an existing work.
There are already a number of systems that meet our definition of generative AIs, some of which have been around for decades. David Cope’s Experiments in Musical Intelligence software, or Emmy, has been producing novel music based on existing works since the 1980s.[6] Later, Cope “co-wrote” a number of compositions with "Emily Howell," an AI trained on Emmy’s works.[7] The Painting Fool started in 2001 as a system that parsed existing images to render them in various artistic styles.[8] Later experiments connected The Painting Fool to facial recognition and text processing software, allowing it to create context-specific works.[9] The Painting Fool can now combine the technical skills it has learned with an evolutionary algorithm to compose and illustrate novel scenes, such as city skylines.[10]
More recent generative AIs have garnered significant public attention. Consider Google’s open-source DeepDream software, an artificial neural network that can be trained to recognize specific images, such as animal faces, then detect and enhance similar patterns in unrelated images.[11] Some of DeepDream’s outputs appeared in a gallery show in San Francisco in 2016, where they sold for up to $8,000.[12] In another prominent example, employees of J. Walter Thompson Amsterdam developed machine learning software that they fed a diet of straight Rembrandt, capturing data from the paintings’ subject matter to the topography of the master’s brushstrokes.[13] The software analyzed the inputs and then created (by means of 3-D printing) a new “Rembrandt,” typical in all ways of the artist’s style. On the musical front, Sony’s Flow Machines software, which can learn and reproduce musical styles, includes an AI composer that can act as an assistant to human musicians.[14] Another service, Jukedeck, sells customized AI-generated audio tracks.[15]
II. The Anatomy of Art-generating AI Systems
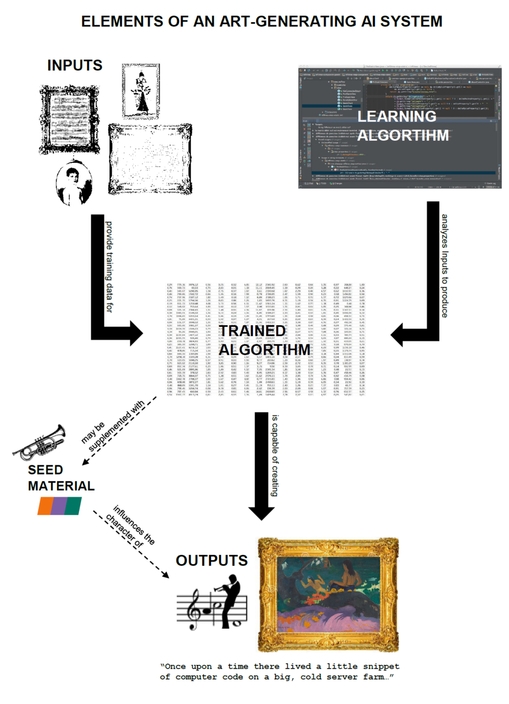
Even under our narrowed definition, the AI-generated art projects we’ve encountered in our legal practice and our research have each been distinct, representing a wide range of technical approaches and artistic goals. However, from a structural perspective, they possess essential commonalities. We have identified four key elements of generative AIs:
- Input. The Inputs are the existing works of art that are fed to the system to train it. The set of Inputs can range from a small, homogenous corpus[16] to tens of thousands of diverse works.[17]
- Learning Algorithm. The Learning Algorithm is the machine learning system that operates on the Inputs. The Learning Algorithm may consist of off-the-shelf software, custom code, or some combination of the two.
- Trained Algorithm. The Trained Algorithm is the information that the Learning Algorithm has generated from its operation on the Inputs, along with instructions for turning that information back into a work. Depending on the specific machine learning approach used, this information may include recognizable fragments of the Inputs[18] or may be more abstract, such a series of concepts or decision points.[19]
- Output. The Outputs are the works produced by running the Trained Algorithm. Outputs are often generated from a “seed” that gives the Trained Algorithm a starting point, but can also be created from random starting points, with or without constraints.
*
While the taxonomy above is not the only way of understanding generative AIs, it is a particularly useful one for the purpose of assessing intellectual property rights. Claims of authorship and ownership of AI-generated art can be hazy as to the overall project, but are typically crystal clear with respect to each of these elements. Using this anatomy, it becomes manageable to address the complicated questions of ownership and authorship that AI-generated art raises. Breaking a generative AI down into these four elements enables each party to reserve rights in the elements for which they are solely responsible and negotiate rationally about the others. In the following sub-sections, we examine each element in greater detail.
A. Inputs
For purposes of this Comment, we have only considered generative AIs that rely on some form of preexisting art as training data. We refer to this training data as the “Inputs.” Generally, art-generating AIs rely on multiple Inputs, ranging from dozens up through millions. In some cases, the range of Inputs is tightly defined by the humans involved with the project (e.g., the Rembrandt paintings that were analyzed for the Next Rembrandt project), while in others, the set may be broader, shift over time, and even be the output of another AI.[20]
Inputs are distinct from seed materials, which are discussed in Part III.C. Inputs are used to teach the Learning Algorithm how to generate art; seed materials provide a prompt for the generation of a specific Output. For example, Google’s DeepDream AI can be trained on Inputs to recognize a specific type of pattern, such as animal faces. Once it is trained, it can detect and enhance those patterns in a seed image, creating an Output that resembles the seed image but is clearly influenced by the Inputs.
B. Learning Algorithm
The “Learning Algorithm” is a machine-learning algorithm that is capable of identifying the relevant characteristics of the Inputs, then storing that information in a data structure (forming the Trained Algorithm). The Learning Algorithm may be designed with a particular type of Input in mind, but exists separately from its Inputs. There are number of approaches to machine learning, and any given approach can be implemented in any of a number of programming languages, so the universe of possible Learning Algorithms is vast.
Because machine learning techniques vary so widely, it is not possible to describe every type of Learning Algorithm in this article. Instead, we point out the characteristics of that are most likely to affect copyright analysis. First, different algorithms analyze Inputs in different ways, and may store actual pieces of the Inputs[21] or only abstract representations.[22] Second, the Learning Algorithm may include some degree of human feedback about the learning process, sometimes referred to as “active learning.” Third, not every Learning Algorithm will be developed from scratch—there are numerous open-source and proprietary software packages that provide machine learning capabilities. As we will discuss in the second part of this series, these aspects of the Learning Algorithm can have an impact on the ownership of the Trained Algorithm and Outputs.
C. Trained Algorithm
While the Inputs and the Learning Algorithm are typically developed independently of each other, and may predate the conception of the AI-generated art project in question, what we term the “Trained Algorithm” is unique to the individual project. The Trained Algorithm contains a data structure produced by the operation of the Learning Algorithm on the Inputs; running the same Learning Algorithm on different Inputs, or vice versa, will result in a new, unique Trained Algorithm The degree to which any given Input is identifiable in this data structure depends on both the number of Inputs and the type of Learning Algorithm used. In any case, a large amount of the information in the Trained Algorithm will consist of probabilities and operations, rather than as anything resembling art. This distinguishes the Trained Algorithm from the Outputs, which are readily appreciable as art to the untrained eye or ear.
The Trained Algorithm is the element that generates the Outputs. To do so, it takes the data generated about the Inputs and, in effect, runs the process in reverse: it takes chunks and representations and turns them into artwork. Many generative AIs require seed material—a template, grammar, or starting point for generating an Output. The seed material could be hand-picked or selected by the AI itself. For example, the Painting Fool has produced a series of collages by reading news stories, finding relevant images in public repositories such as Google Images or Flickr, and rendering them in an artistic style.[23] Other Trained Algorithms are capable of creating art from scratch (without a seed) based on their knowledge of the composition and structure of the Inputs.[24]
In some ways, isolating this element from the other parts of the generative AI is the heart of this anatomy. It is the element that distinguishes generative AIs from earlier technologies such as sophisticated photo editing software, and the element that is least intuitive to those without experience in this field, who are often tempted to conflate it either with the Learning Algorithm or the Outputs. In fact, it represents the unique combination of the Inputs and the Learning Algorithm, which raises complex ownership questions that we will address in the second Comment of the series.
D. Outputs
The ”Outputs” are the works produced by a generative AI, each the result of an operation of the Trained Algorithm. Outputs take a form recognizable as “art” in the sense that they are not code or data, but rather a drawing, piece of music, or other tangible work. We come to them last because this anatomy is structured from a process perspective, but for most people, the Outputs are the essential, and most compelling, element of the system. Certainly, they are element that generates headlines.[25]
While individual systems may vary in terms of the success they achieve—in that their Outputs may or may not be original or aesthetically satisfying, or fulfill the aims of the people driving the projects—for purposes of this Comment, we have focused on the generative AIs that do produce novel and surprising Outputs. We confine ourselves to these high-quality systems because their Outputs are something more than mere reproductions of their Inputs, meaning that the copyright analysis is significantly more interesting. As we note in Section I, there are numerous such systems already extant, and we don’t doubt that more will continue to emerge.
III. Conclusion
The anatomy we have presented in this Comment—understanding an art-generating AI system as composed of Inputs, a Learning Algorithm, a Trained Algorithm, and Outputs—forms a foundation for thinking clearly about the questions of ownership and control that arise in connection with such systems.
In the second part of this series, we’ll provide some thoughts about how copyright law might apply to each element. For example, should a Trained Algorithm be considered a joint work of the author of the Inputs and the author of the Learning Algorithm? Does the owner of the Trained Algorithm automatically own all of that algorithm’s Outputs? We’ll also provide some thoughts on practical considerations in drafting licenses in connection with generative AIs, such as the impact of the incorporation of preexisting code into a Learning Algorithm or limiting future creation of Outputs.
It is our hope that this series will advance the valuable work being done in computational creativity and AI-generated art by enabling attorneys to support these projects effectively.
Special thanks to Peter Wills for his assistance with this Comment.
[1] See, e.g. Gemma Kappala-Ramsamy, Robot Painter Draws on Abstract Thoughts, The Guardian, Apr. 1, 2012, https://www.theguardian.com/technology/2012/apr/01/robot-painter-software-painting-fool; Simon Colton, About Me, The Painting Fool (2017), http://www.thepaintingfool.com/. (discussing a program called The Painting Fool); Tim Nudd, Inside “The Next Rembrandt”: How JWT Got a Computer to Paint Like the Old Master, Adweek, Jun. 27, 2016. (on an AI that mimics Rembrandt) .
[2] Benjamin L.W. Sobel, Artificial Intelligence’s Fair Use Crisis, Columbia Journal of Law & the Arts pt. II (forthcoming).
[3] Simon Colton & Geraint A. Wiggins, Computational Creativity: The Final Frontier?, Proceedings of the 20th European conference on artificial intelligence 21, 1 (IOS Press 2012) (so defining “computational creativity”).
[4] Machine learning algorithms are a subset of AI algorithms. See Ian Goodfellow et al., Deep Learning, fig. 1.4 (2016). For example, both Harold Cohen’s AARON program and Jon McCormack’s Niche Constructions program implement AI algorithms that are not machine learning algorithms. AARON is a program that “model[s] some aspects of human art-making” according to rules; although “autonomous” in that it does not rely on human input once it begins, it “is not a learning program.” See Harold Cohen, What is an Image?, Proceedings of the 6th International Joint Conference on Artificial Intelligence - Volume 2 1028, 1,3 (IJCAI’79, Morgan Kaufmann Publishers Inc. San Francisco, CA, USA 1979). Niche Constructions, meanwhile, uses line drawing agents that move around a 2D surface. The agents have properties that are inherited by their descendants, and a rule that makes them “die”. The canvas is complete when all agents die. Jon McCormack & Oliver Bown, Life’s What You Make: Niche Construction and Evolutionary Art, Applications of Evolutionary Computing 528 (2009).
[5] The Electric Sheep project offers one example of such an evolutionary algorithm. There, an algorithm creates images, which humans grade for artistic appeal. The better-scoring images “reproduce” more. See Scott Draves, Evolution and Collective Intelligence of the Electric Sheep, in The Art of Artificial Evolution: A Handbook on Evolutionary Art and Music 63 (Juan Romero & Penousal Machado eds., 2007).
[6] Keith Muscutt & David Cope, Composing with Algorithms: An Interview with David Cope, 31 Computer Music Journal 10 (2007).
[7] Id.
[8] Colton, supra note 1.
[9] Id.
[10] Id.
[11] Alexander Mordvintsev et al., Inceptionism: Going Deeper into Neural Networks, Google Research Blog (Jun. 17, 2015), https://research.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html.
[12] Katherine Boehret, Google’s Algorithms Created all the Art for an Exhibit in San Francisco, The Verge (Mar. 1–2016), https://www.theverge.com/google/2016/3/1/11140374/google-neural-networks-deepdream-art-exhibition-san-francisco.
[13] Nudd, supra note 1.
[14] AI Makes Pop Music in Different Music Styles, Flow Machines (Sept. 19, 2016), http://www.flow-machines.com/ai-makes-pop-music/.
[15] Jukedeck R&D Team, Audio Synthesis at Jukedeck, Jukedeck Research Blog (Dec. 1, 2016), https://research.jukedeck.com/audio-synthesis-at-jukedeck-788239d65494.
[16] As in The Next Rembrandt. Nudd, supra note 1.
[17] As with Flow Machines, supra note 14.
[18] See id.
[19] A neural network like that underlying Deep Dream is one example. See Mordvintsev et al., supra note 11.
* The vector image of a trumpet player in the outputs was uploaded to Wikimedia Commons by user Stannered. This vector image was created with Inkscape from https://en.wikipedia.org/wiki/Image:Jazzstubartwork.png. This file is licensed under CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=1921973.
[20] This is how the Emily Howell AI generates music. See Muscutt & Cope, supra note 6.
[21] As with an algorithm that generates Markov sequences. See François Pachet & Pierre Roy, Markov Constraints: Steerable Generation of Markov Sequences, 16 Constraints 148 (2011).
[22] As with many deep neural networks. See Leon A. Gatys et al., A Neural Algorithm of Artistic Style, arXiv:1508.06576 [cs, q-bio] (2015).
[23] Simon Colton, The Painting Fool: Stories from Building an Automated Painter, in Computers and Creativity 3, 30 (Jon McCormack & Mark d’Inverno eds., 2012).
[24] Simon Colton, Automatic Invention of Fitness Functions with Application to Scene Generation, Applications of Evolutionary Computing 381 (Lecture Notes in Computer Science, Springer, Berlin, Heidelberg Mar. 26, 2008).
[25] See supra notes 1 & 12.